Dimensions in Linear Algebra
Table of Contents
I. Vectors
Behold a three-dimensional vector space:
And a vector:
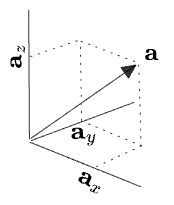
Here I’ve labeled the components of the vector called
But if there were more than three dimensions, we couldn’t simply draw a vector in perspective. Instead, let’s collapse the extras onto a single axis:
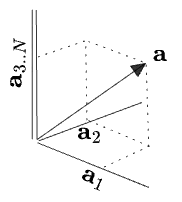
The double line represents “one or more dimensions”—the rest of the
Maybe you even decide to forget how many dimensions are in
But there are various ways to perform this reduction—how do you pick? An obvious choice is to map that component
But that isn’t the only option; you could, for example, project to a single one of the
Or you could go the opposite direction: maybe you thought you were working in 3 dimensions, and then: more pop out! You “unreduce” one dimension into a whole
Now, if you have one vector
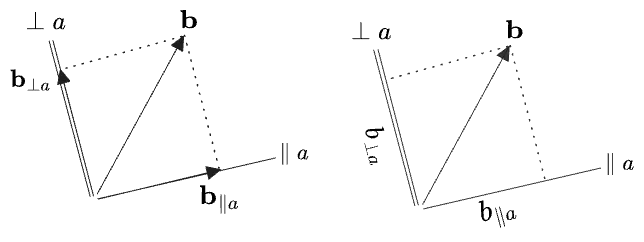
Here I’ve adopted a few conventions:
and are subspaces, and will not be typeset in boldface. These are labeled in the diagram as lines without arrows, while vectors have arrows at the end. Their “negative” halves are not depicted (what would negative mean?)—but it might be useful to depict these in other instances. - A double line is again used for a subspace of greater than one dimension. Here, in
dimensions, will be -dimensional. - On the left are shown the vector projection
and rejection . - On the right, the scalar projection
and rejection are shown. The “sides” of are labeled something like their lengths, but should be thought of as containing components. - These projections and rejections are written to suggest that they are operations between
and the subspaces and , rather than between and the vector itself. This is helpful because it avoids having to make reference to any particular basis on the subspace .
The same decomposition as an equation is:
More conventions:
In any case, once we’ve defined
So whatever
The right diagram above depicted a vector in terms of its two components
Let’s now throw out the rule that “right angles represent orthogonal dimensions”. Instead, for the rest of this post, we’ll use a half-axis starting from the origin to stand for an entire dimension, orthogonal to all the rest, no matter what angle they’re drawn at. Double-lines will represent multiple dimensions collapsed into a single half-axis. We can then fit more than two or three dimensions in a single diagram. Here’s a 10-dimensional space and a vector
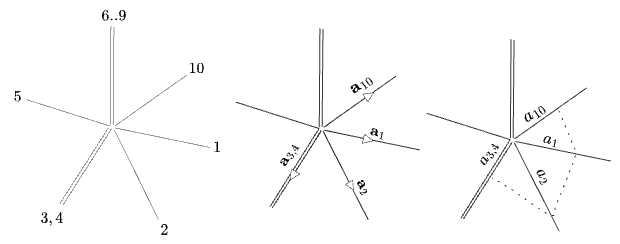
The obvious definition of an expression like
Is the polygon anything? Probably not. It’s quite underdetermined: it’s only defined only up to the signs of the components and up to the choice “projection” on any multi-dimensions (the
II. Matrices
We can do something similar with a matrix. Suppose you have some rank-10 real matrix
That is, this matrix:
- scales its first two eigendimensions by
respectively. - rotates dimensions 3 and 4 into each other, while scaling by
. - scales dimensions 5 through 9 by a common factor
. - annihilates dimension 10.
This can be visualized as follows:
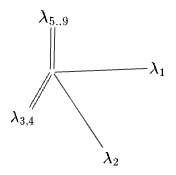
This could be read as a vector along the lines of the previous section, but I don’t think that interpretation would be very meaningful. Instead this should now be thought of as a simply standing for the diagonal representation of the matrix itself.
The first two eigenvalues are the biggest, so we could approximate this matrix by only its first two “principal components”, i.e. by zeroing all but the first two eigenvectors, defining a new matrix
Explicitly:
This is something like a “principal component analysis”. The action of
where the last expression is to be understood as a standard inner product.
We can equivalently think of this PCA-like-reduction as a reduction of the vector space to three-dimensions, where the first two dimensions are chosen as principal eigendimensions. Under this reduction
or, graphically:
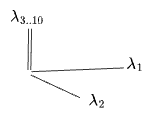
where
The action of
where
Meanwhile the reduced-truncated
One constraint we can place on the meaning of
Then if we take
we get an interpretation of
(All this would be more general if working with singular values, but I can’t be bothered.)
Another “reduction” operation would be to define
If we can reduce away some of the dimensions of a matrix, we can reduce away all of them, getting a single scalar:
![]()
Some good candidates for the “one-dimensional reduction” of a matrix are:
- the determinant, or geometric mean, of eigenvalues
- the trace
- the Frobenius norm
- the sum of absolute values of eigenvalues/SVs.
- the largest eigenvalue, or perhaps its absolute value. Same for SVs.
This is really the starting point for this whole line of thinking: it seems that there are multiple sensible ways to “reduce” a linear operator to a single number. Each ought to be able to be thought of as operations on the vector space instead on the operator, and it should be possible to “partially apply” any of them to give successive “approximations” to the original operator.
My point here is not really to discover a new matrix operation, but to arrive at a “unified framework” in which to understand a number of disparate linear algebra concepts—in particular, from which to motivate them. The idea of such operations as applying to the space rather than to the operator is highly suggestive to me—it is something like
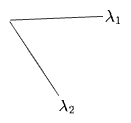
Now, when we mapped
Or, consider rotating around dimension 2 (rotating dimension 1 into 3), before and after the unfolding. Before,
This looks like like the reverse of what we just did with the matrix

And of course, we can equally well imagine folding 10 dimensions into 2 or 3 rather than 1, and the same “choices” will arise.
All of this isn’t so strange: we do this to get
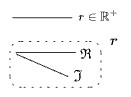
And there are different ways you can do it. The obvious one is to identify
Comments
(via Bluesky)