On Elementary Statistics
Somehow I managed to make it through an undergraduate physics degree, two years of grad school, and three years of work as a data scientist, without ever taking a course in statistics.
I picked up a fair amount through courses and ambiently on the intellectual internet, but this education was incomplete, and it turned out to be a fairly noticeable handicap to be less-than-fluent in the common knowledge of other professional math-people—not surprisingly.1
Yet mathematics when actually applied to the world is quite a bit like a skill, and statistics is the central vocabulary of this practical skillset. Somehow I missed it entirely.
This is how I came to work through MathAcademy’s high-school-AP-level statistics course remedially at the age of 35, despite my mathematical experience substantially exceeding what it expected of me.
This turned out to be something of a rare opportunity—to encounter something as a student but with an adult’s ability to examine my experience. Here’s what I found.
Table of Contents
Random Variables
The moment we encounter the “random variable” we are confused. There is a sense of “too many cooks” having spoiled something—of an abstraction created for one purpose and then formalized with a different “sense”, of programming in a codebase without a coherent architecture; no unifying sense of “intelligent design”; no other mind for my mind to mirror.
What exactly is my problem? I am not sure whether my issue is with the naming or the pedagogy or the concepts themselves. I will find out by trying to explain it.
One begins statistics with elementary calculations of probabilities—permutations, combinations, replacements, conditionals, Bayes’ Theorem. The mental gestures entailed are, first, the mere counting of possibilities, which proves incredibly effective, and second the clever application of the rules for transforming these counts. With some practice one starts to see the patterns to these operations and gets a feel for their power. All is grounded in the notion that a probability is defined as a ratio of measures of sets
which is basically compatible with both a frequentist/objective “long run relative frequency” and a Bayesian/subjective “degree of belief” view, so long as the latter assigns a consistent meaning to the counting operation
At this point we have grown accustomed to the differing treatment of data depending on whether it is “categorical”, “ordinal”, or “numerical”, and for numerical data by whether it is discrete or continuous, or in general by its domain
At this point we have basically introduced the thing to be called a “random variable”—it is simply an assignment of numerical values to events.
We assign probabilities to real numbers
Often the elements of
The random variables
But these random variables are at this point very general things, not particularly “random” and not particularly “probabilistic”; the term “random variable” is not well-motivated from this direction. These constructions are really applicable to any “measurable set”, and their nice properties derive mainly from their being vectors, though, pedagogically, we of course do not speak of “measurable sets” or “vectors” in the abstract at this point.
So we will try to arrive at the idea of a “random variable” from a second direction. We start by looking at a collection of data and label it with an integer in the obvious way
And of course we would like to express things like a “mean” as a function of the data
which suggests interpretations both as an “operator”
Then, starting from the original notion of “probabilities as counts”, we find ourselves trying to ask the question: given a hypothesized underlying probability distribution for the
and we declare that these variables are “random variables”. Likewise we notate a “random vector” of random variables as
So far we have not really said how the probabilities work—that these should be considered “random” has no precise meaning. At present our random variables are something like the arguments to a function in code:
function calcSomeStats(Xs: Array[Real]):
X_avg: Real = Xs.sum() / Xs.length()
f_of_X1: Real = f(Xs[0])
... etc.And, for now, the
Then we additionally assert that the input r.v.s
To express this idea of a random variable in software, we would have to write some kind of DAG structure which treats the inputs and derived nodes equivalently:
function myModel():
m = model()
Xs: RandomVector = m.input()
X_avg: RandomVariable = Xs.sum() / Xs.length()
f_Of_X1: RandomVariable = f(Xs[0])
return m
m = myModel()
m.set_input(dist=Normal(mu, sigma^2), samples=N)Now the name “random variable” feels appropriate: these are “variables” which are “random”. We can go on to calculate further statistics like variances and standard deviations, and these too will be the same type of thing too—random variables.
Conveniently, the “types” of
The code examples clarify that the gesture being made by the use of random variables is a familiar one from software: the shift from an imperative program flow to something like a “late binding” representation of a program, often seen in DSLs, which allows additional information to be carried alongside the flow of the program (here, the arithmetic).
A bit of discomfort at this point arises from the fact these notations suggest that
To arrive at the technical definition of a random variable we need to take one more step. We assert that the probability
In the r.h.s. we are using
where
Note this random-variable-as-a-function is the same thing we came up with when we want to assign numerical values to ordinal or categorical data! We have only reached it from a different direction.
What we have here is best expressed in code as a SQL groupby
SELECT
X(w),
SUM(p(w)) as w
FROM omega AS w
GROUP BY 1but there is not really an obvious way to use this construction in a modeling context.
But we go on to use these functions in strange ways,
where
Now that I’m seeing this clearly, it looks quite strange. This is something like notating a “restriction” with a predicate,
Here it perhaps makes sense to drop the
I think I have located my confusion. The technical random variable-as-function is really the first thing you would do to assign probabilities to a set. But the name “random variable” and its notations make the most sense when viewed as “placeholder variables understood to be equipped with probability distributions”, and it’s hard to intuit how the technical definition as a function winds up supporting this.
To my eye the name “random variable” ought to be reserved for the notation
A different word should be used for the sense of
I really don’t even like using
Perhaps the best thing to do would be to allow a predicate like
Kolmogorov’s View
Now another discomfort I feel with basic probability.
The problem roughly has to do with the relationship between the variables and processes under discussion and the enclosing “universe” which these inhabit.
Suppose you are handed one random variable
There is absolutely nothing stopping you from defining a new random variable
Something already irks me. It feels strange that we can whip up new product spaces like
The natural way we are introduced to a product of sets is by thinking of the two sets as the sides of a rectangle, or entries of a tuple, and of course their cardinalities multiply. Each logical construction we imagine existing in a featureless intellectual vacuum (much like the thought of experiments of Galileo), and we develop the habit of waving into existence new entities in that vacuum without much of a thought. But this is only a model of physical reality (again like Galileo) and, while it is effective at isolating concepts and factoring them into their constituent abstractions, it is not true…
Consider the following example from Jaynes. The probability of a proposition
Evidently this sum-over-penguins was always present in premise
Let us try to write this another way, not as a logic of propositions but as a “sample space”, with
The penguins live in
- system
itself, with states - the part of the rest of the universe which correlates with or contains information about
, which I’ll denote by - the rest of the universe,
.
that is,
Anything in
This is a statistical-physics-inspired view:
I am trying to sketch my way towards the sense in which, when we add two unrelated random variables
The claim is that we see in an example like the Jaynes’ penguins that probabilistic language about beliefs and propositions always existed in relationship to irrelevant states and information.
It feels as though there is a different way of thinking about probability distributions which makes this manifest in the first place: that, say, declaring the existence of a sample space
In this view the act of writing
I don’t have much more to say on this now, but it reminds me of a number of other observations. It feels helpful to link them together.
I originally came by the sense of this other “view” of probabilities in statistical mechanics. It is reminiscent also of reaction network theory and is related to my series of sketches on dimensions. I am also reminded of the way the first term in the series expansion of the Shannon Entropy admits an interpretation as counting “distinctions”, which I mention here—in particular, the picture below of an uneven probability distribution as being described, not in terms of an equivalence relation on an underlying set, but an inequivalence relation:
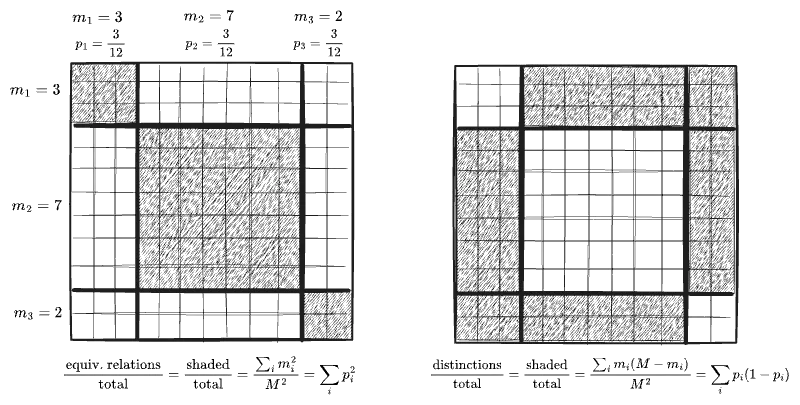
I suspect that the view I am grasping for would, if achieved, be a complete inversion of thinking about probability. My hunch is that this is the way we should be thinking of and teaching probability in the first place—that some immense amount of misunderstanding arises from attempting to extend that “idealized sets in a vacuum” view far beyond the point where it is sane to do so. In the inverted view, Jaynes’ penguins would be entirely unsurprising—because it should be obvious in the first place that any distinction you are not making could be made and would carve up your sample space further.2
Confidence Intervals
Let me spell out a basic confidence interval calculation before I start complaining.
We begin with some data
- the mean
of a sample of points from this process will therefore be distributed with the same mean and variance . - the sample variance
, standardized, will be distributed . - the t-statistic
, for a given true mean , will have a distribution.
Then we can test a specific candidate
Now: a notation is sorely missing! It is relatively straightforward to write the three distributions I just spelled out, but the remaining steps of the process are taught by a patchwork of paragraphs and equations, and are far harder to follow the logic of; as a result the exact logical content of a “confidence interval” is obscure to many (which obscures, among other things, how objectionable it is!)
To repair this we need the “interval notation”
Usually
We also need to allow our functions to map intervals to intervals:
This only works for nice enough functions, but we can always map sets to sets.
With these tools we may express the rest of the confidence interval argument purely in equations. Here
This to me is crystal-clear: we reject any
Likewise when we estimate a true variance we could perform an analogous calculation on the
These kinds of manipulations of sets are, I think, a programmer’s instincts at work. Conventional written mathematics prefers certain kinds of abstractions and abuses of notations and shies away from others; programmers are less shy about re-defining syntaxes. In particular, using
In short, we ought to let a “confidence interval” be a particular instance of a general thing, an “interval”!
That’s enough for now, though there’s plenty more to say. In a separate post I also intend to give my thoughts on MathAcademy in particular.
-
We moderns tend to underrate the degree to which math is a skill like any trade, and the degree to which a mêtis—a body of practical knowledge, acquired by experience and mentorship—is involved in rendering it useful. The math we learn in school has a completely different sense to it, and only pays lip service to practical applications, far short of what would be required to acquire this mêtis; to the extent we encounter mêtis it is in spreadsheets, and in programming if we partake of those classes. In school, instead, we learn a very different sense of mathematics, which aspires to entirely different ideals than would a useful skill. High-school math is learned in a manner resembling Latin grammar, all vocabulary and declensions and inflections and the like, without ever even reading anything aloud, much less conversing or arguing. Higher math is like an art, which aims to bring into view a tremendous edifice of logical implication, which must be understood in compressed forms and maps only, being too immense to comprehend in totality; Category Theory of course is well-directed towards this ideal, though I wonder if past generations of mathematicians were essentially doing something else. Physics and computer science, then, seem to undertake a slightly different “gesture” of the mind than pure-math—not exactly “compression” but the “factoring” of physical reality into discrete components, building-blocks, and principles; a sort of middle-ground between math and the mêtis of real work.3 ↩
-
Furthermore, such a view might encourage an entirely different approach to rational thought. How much of modern thinking is downstream of the paradigmatic ways of thinking in which we are well-trained by early educations in math and physics? It is impossible to speak of such things without seeming crazy, yet, consider the following example: today’s philosophical discourse gives an enormous amount of attention to utilitarianism, and to attempting to devise the exact assignment of “lives” and “life-years” and “pain qualia” and the like to “moral value”, e.g. in Effective Altruist circles and similar. Is this not directly a consequence of a probabilistic way of thinking? To attempt to model morality by assigning equal moral value to each human life is to impose a “uniform distribution” on a sample space of human lives which is, in reality, devoid of any “quantity” akin to moral value. This has always seemed insane to me—perhaps a consequence of missing out on a statistics class in my formative years. Human lives are, in reality, unalike things—incommensurable and non-fungible, unless we choose to assign them real-number or at least ordinal values. The choice to do so is itself a moral act, and may be an appropriate one in certain contexts (e.g. a state with a duty to treat its population equitably) but is, to my eye, an absurd view for a human being to hold, and is at odds with the natural moral sentiments out of which ethics arises.4 ↩
-
I have come to see the abstract mathematics as a dreamlike pursuit—to endlessly form connections and see clearly as an end in itself, towards no other end in particular—grasping to comprehend a certain God essentially as a mystical act. To be “useful” is nearly antithetical to the aims of the mathematical mind. Only wartime (the atom bomb, encryption, competitive pressure, etc.) can really divert this mystical inclination downward to vulgar reality, where, of course, it turns out to grant incredible power. The reclusive wizards of modern fantasy are remixes of mathematicians and physicists, above all; their aims of this memetic archetype are always obscure; at best they are servants of some divine mission (e.g. Gandalf) invisible to worldly mortals; at worst their power is employed in selfish self-interest and always reads as evil. ↩
-
Likewise it is absurd to my eye that the “trolley problem” is considered interesting at all—it is the philosophical equivalent of a Galilean thought experiment in a vacuum, and depends on and encourages a view of morality in terms of identitarian features, or the mere counting of bodies, rather than the context of the scenario in the enclosing world. In reality our judgment of just action in such a scenario would depend almost entirely on how the scenario came to be—whether duties were neglected, whether anyone was to blame vs. fate alone, whether the scenario had occurred before or might recur. Morality, in my view, has nothing to do with such scenarios considered in a vacuum. One may counter that physics gets quite a bit use out of thought experiments in vacuums, but physics does not truly consider vacuums—there is always an external force
, or a gravitational field , or ingoing or outgoing edges to a Feynman diagram—the external world is factored into its atomic interactions, diagonalized w.r.t. an operator which is linear over the dynamic in question, and thus its thought experiments lead to genuinely composable abstractions. Not so for the trolley problem, not generally, though we try to add such edges, “what if one of the people is Hitler?”, “what if they’re suicidal?”, etc.—morality does not decompose; these exercises are nonsense; entertaining them encourages a paradigm of thinking in the Kuhnian sense which is unable to contemplate non-utilitarian moralities entirely. ↩